Redshift 是亚马逊提供的列式存储数据库。和传统的关系型数据库不同,Redshift主要是列式存储,应用场景主要是OLAP。相对于OLTP,应用要求快速定位到某一条记录,OLAP更多是数据的聚合,或者是数仓结构(相对较少的join,读取指定范围内的数据而不是单条数据)。
排序键
根据where条件来创建排序键,一个表只能够有一个排序键,可以理解为聚集索引。
可以创建复合排序键,但第一个一般要求highly selective。 可以创建交错排序键,比如多个键过滤的时候,可以用交错排序键。不要使用自增列设为排序键,因为自增最好使用简单的排序键,这样可以用较少的IO获取到数据。
如何确认排序键被用到
可以查看SVL_query_summary查看执行计划是否用到了range-restricted scan。
分布键
如何将数据分布到多个节点上加速查询。分为AUTO, EVEN, KEY,ALL。根据join来设计分布键。
key分布不均匀
如果key本身分布不均匀,会导致数据倾斜,有可能所有数据都分布到1个节点上。
Zone Maps
Zone Maps是存放在内存里面的,记录每个block数据的最大值和最小值,方便查询计划跳过没有必要的block。
Deep Dive
按照下面的query,创建大概340W条记录。
CREATE TABLE pzhong.test_sk(
ID INTEGER IDENTITY(1, 1),
NAME varchar(1024),
PARENT_ID INTEGER
)
DISTSTYLE AUTO
SORTKEY ( ID );
insert into pzhong.test_sk(name, PARENT_ID)
values('aaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaa', cast (random() * 100 as int));
通过下面的query查看zone map分布情况。
select *
from STV_BLOCKLIST
where tbl = 355624
order by col, slice, blocknum
limit 100;
可以看到一些情况。
- 262085 * 4 / 1024 / 1024 刚好是1MB,所以一个block可以存大概26W个integer。
-
数据被分布到4个slice,每个slice有4个block,数据是按照第一列
id排序了的。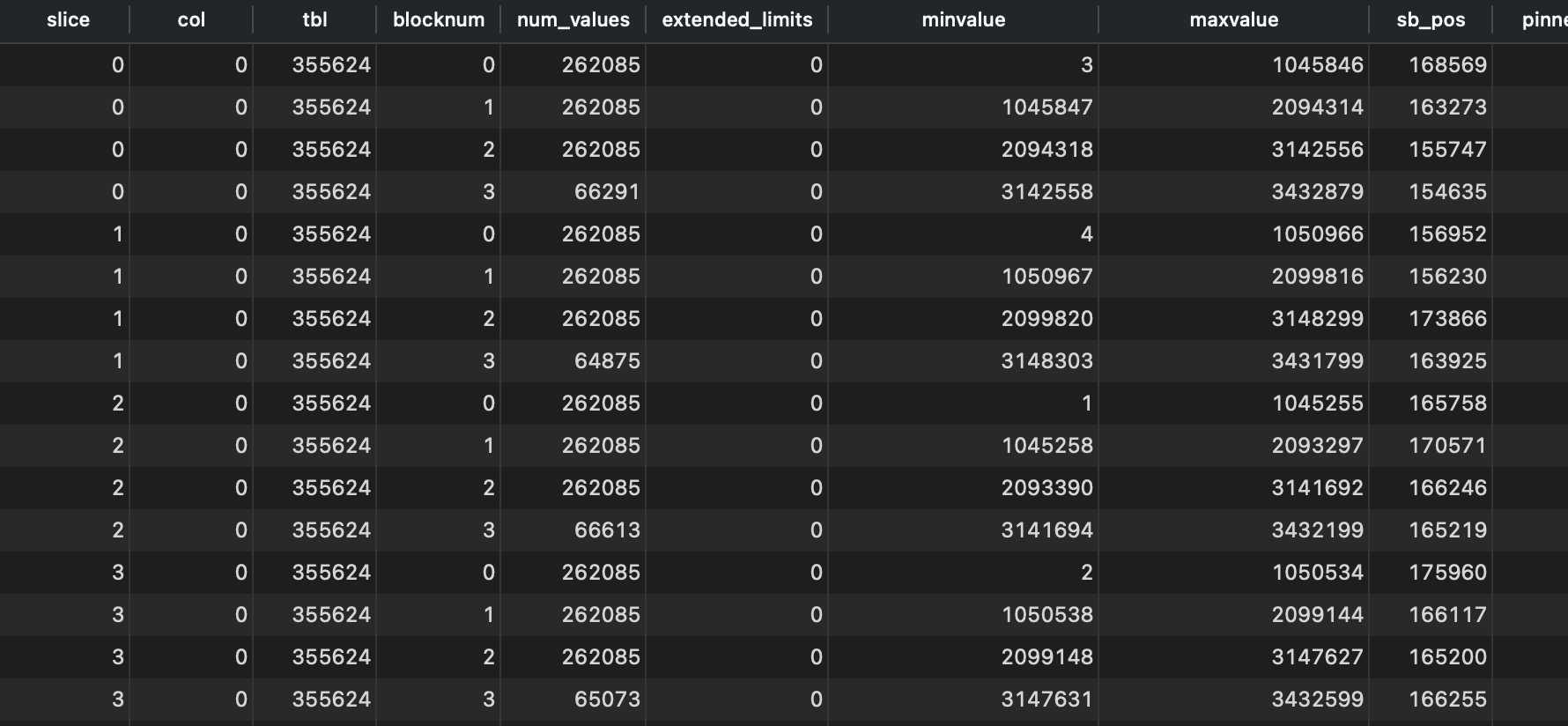
-
但是对于非排序列,就没有那么多block。目测是采用了压缩的原因。

-
每个表除了用户创建的column,还有3个隐藏列,放在最后,分别是INSERT_XID, DELETE_XID, and ROW_ID。

Join的优化
在下面的query中, id 是排序键,但是 parent_id 不是排序键。
explain select c.name, p.name, c.parent_id
from pzhong.test_sk c
inner join pzhong.test_sk p on p.id = c.parent_id
where c.id = 1000000;
导致的结果一个Hash join,可以看见cost很大。
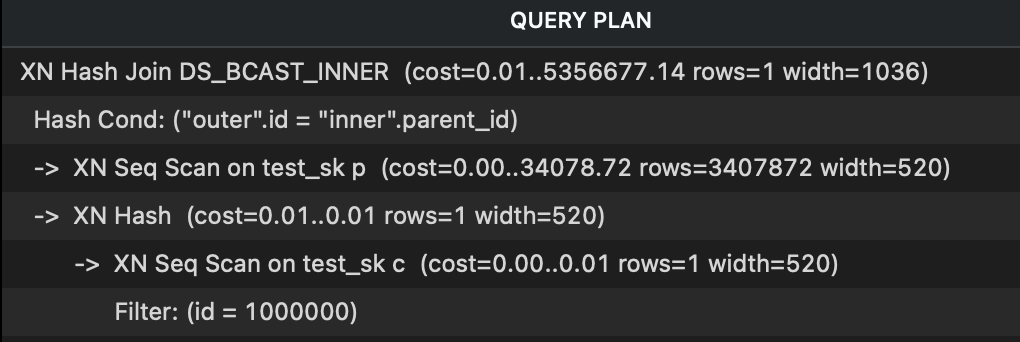
按照KEY分布
如果按照键分布,则性能能够得到比较大的提升。如下图,cost降到了一半(数据集大概多了一倍的情况下) https://aws.amazon.com/cn/blogs/china/amazon-aws-redshift-modify-methods/
CREATE TABLE pzhong.test_sk(
ID INTEGER IDENTITY(1, 1),
NAME varchar(1024),
PARENT_ID INTEGER
)
DISTKEY(ID)
SORTKEY ( ID );
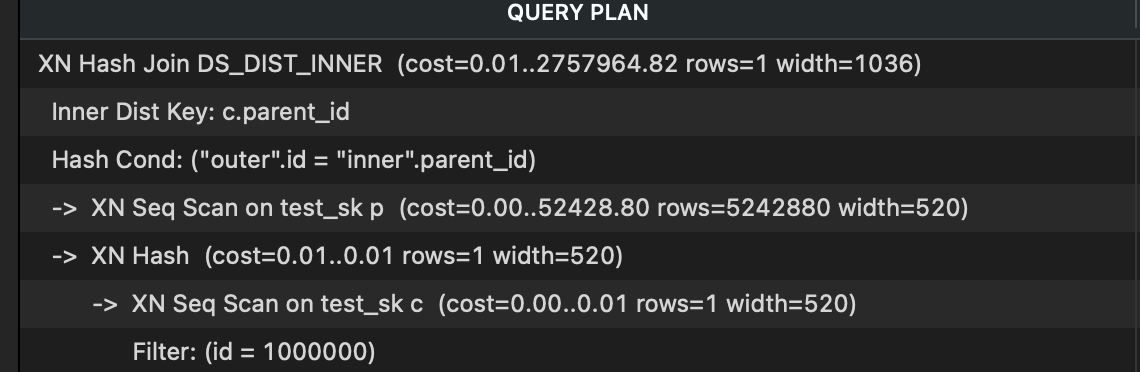
跑下面的query,查看 sortkey_skew_ratio ,越接近于1越好。如果是5,意味着它返回了5倍与它应该返回的数据。
select i.schema as schema_location,
i.table as table_name,
i.encoded as are_columns_encoded,
i.diststyle as distyle_and_key,
i.sortkey1 as first_sortkey,
i.sortkey1_enc as sortkey_compression,
i.sortkey_num as no_sort_keys,
i.skew_sortkey1 as sortkey_skew_ratio,
i.size as size_in_blocks_mb,
i.tbl_rows as total_rows,
i.skew_rows as row_skew_ratio,
i.pct_used as percent_space_used,
i.unsorted as percent_unsorted,
i.stats_off as stats_needed
from svv_table_info i
where i.schema = 'pzhong'
and i.table = 'test_sk'
limit 50;

键分布以后,能够得到一些提升
