准备
最近发现MySQL真的sucks,感觉免费的数据库,只是单纯存取数据,大家就用MySQL,但是如果数据多了以后,MySQL真的不是一般的弱鸡。
Talk is simple, show me the code!
首先,创建一个3000W条数据的表。
CREATE TABLE large_table(
id bigint not null auto_increment,
key varchar(255) not null,
dt datetime
);
DROP PROCEDURE IF EXISTS usp_insert_fake_records ;
CREATE PROCEDURE usp_insert_fake_records(IN cnt bigint)
BEGIN
DECLARE i bigint;
DECLARE key_str varchar(255);
DECLARE rand_dt datetime;
DECLARE min_dt datetime;
DECLARE max_dt datetime;
SET min_dt = '2019-01-01 00:00:00';
SET max_dt = '2020-12-31 23:59:59';
SET i = 0;
WHILE i < cnt DO
SET key_str = CONCAT('ACK-', MD5(UUID()));
SET rand_dt = TIMESTAMPADD(SECOND, FLOOR(RAND() * TIMESTAMPDIFF(SECOND, min_dt, max_dt)), min_dt);
INSERT INTO large_table(k, dt)
VALUES(key_str, rand_dt);
SET i = i + 1;
END WHILE;
END ;
CALL usp_insert_fake_records(10000);
按照上面的步骤,然后再创建不同size的表。
看看前十行数据。
同样在SQL Server上面设置好这样的数据。
CREATE TABLE large_table_1000000(
id bigint not null IDENTITY(1,1) PRIMARY KEY,
k varchar(255) not null,
dt datetime
);
DECLARE @i bigint;
DECLARE @cnt bigint;
DECLARE @key_str varchar(255);
DECLARE @rand_dt datetime;
DECLARE @min_dt datetime;
DECLARE @max_dt datetime;
SET @cnt = 9990;
SET @min_dt = '2019-01-01 00:00:00';
SET @max_dt = '2020-12-31 23:59:59';
SET @i = 0;
WHILE @i < @cnt
BEGIN
SET @key_str = CONCAT('ACK-', CONVERT(VARCHAR(32), HashBytes('MD5', CONVERT(VARCHAR(36), NEWID())), 2));
SET @rand_dt = DATEADD(SECOND, FLOOR(RAND() * DATEDIFF(SECOND, @min_dt, @max_dt)), @min_dt);
INSERT INTO large_table(k, dt)
VALUES(@key_str, @rand_dt);
SET @i = @i + 1;
END;
需要测试的query
select k
from large_table l
group by k
having count(dt) > 1;
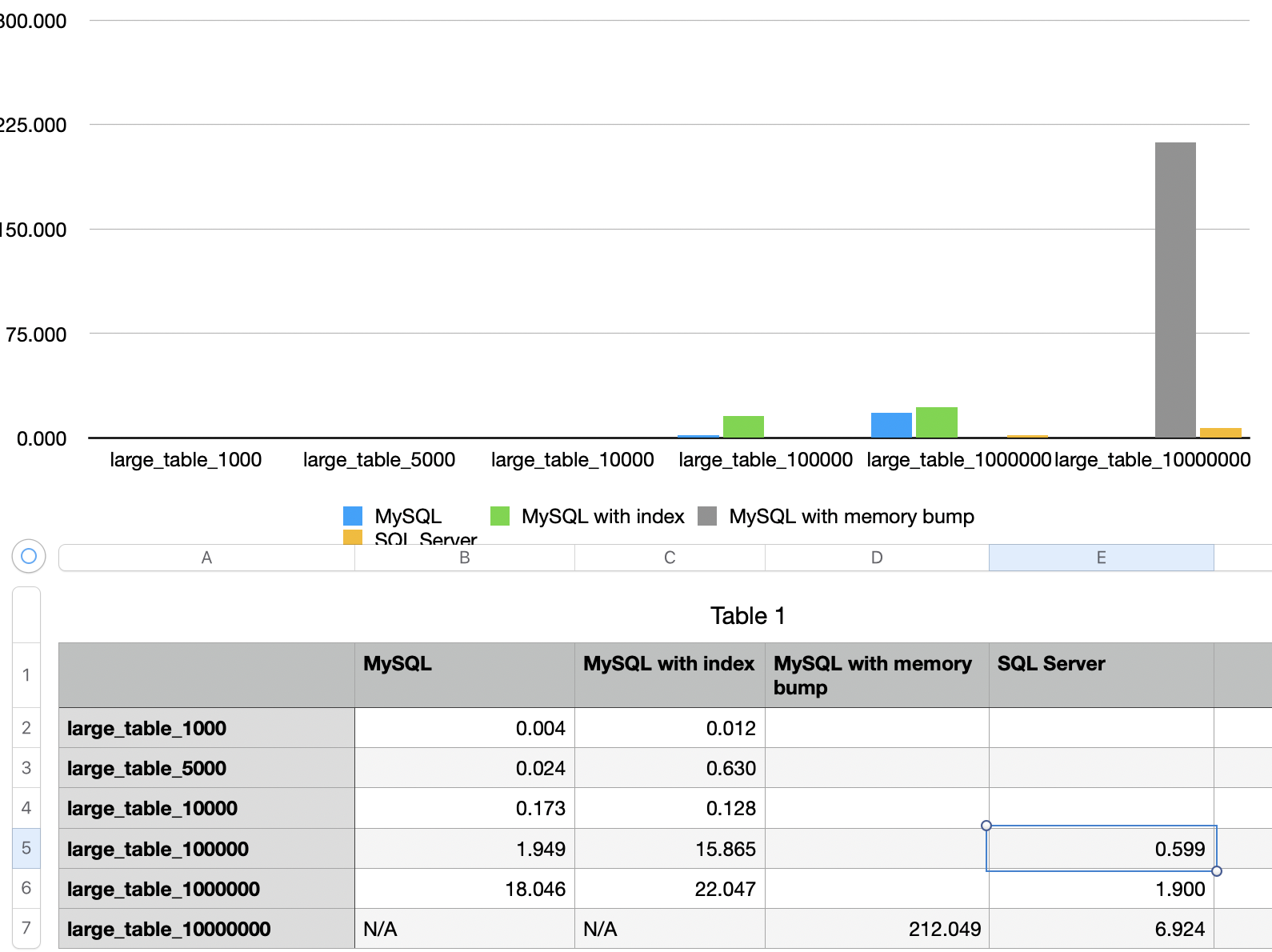
结果
- 在不加内存的情况,1000W条记录就没法出结果。
- 把内存加到1G,勉强可以出结果,但需要212秒。
- SQL Server在这次测试里面(内存2G),1000W条记录只要6.9秒,3000W记录只要22秒。