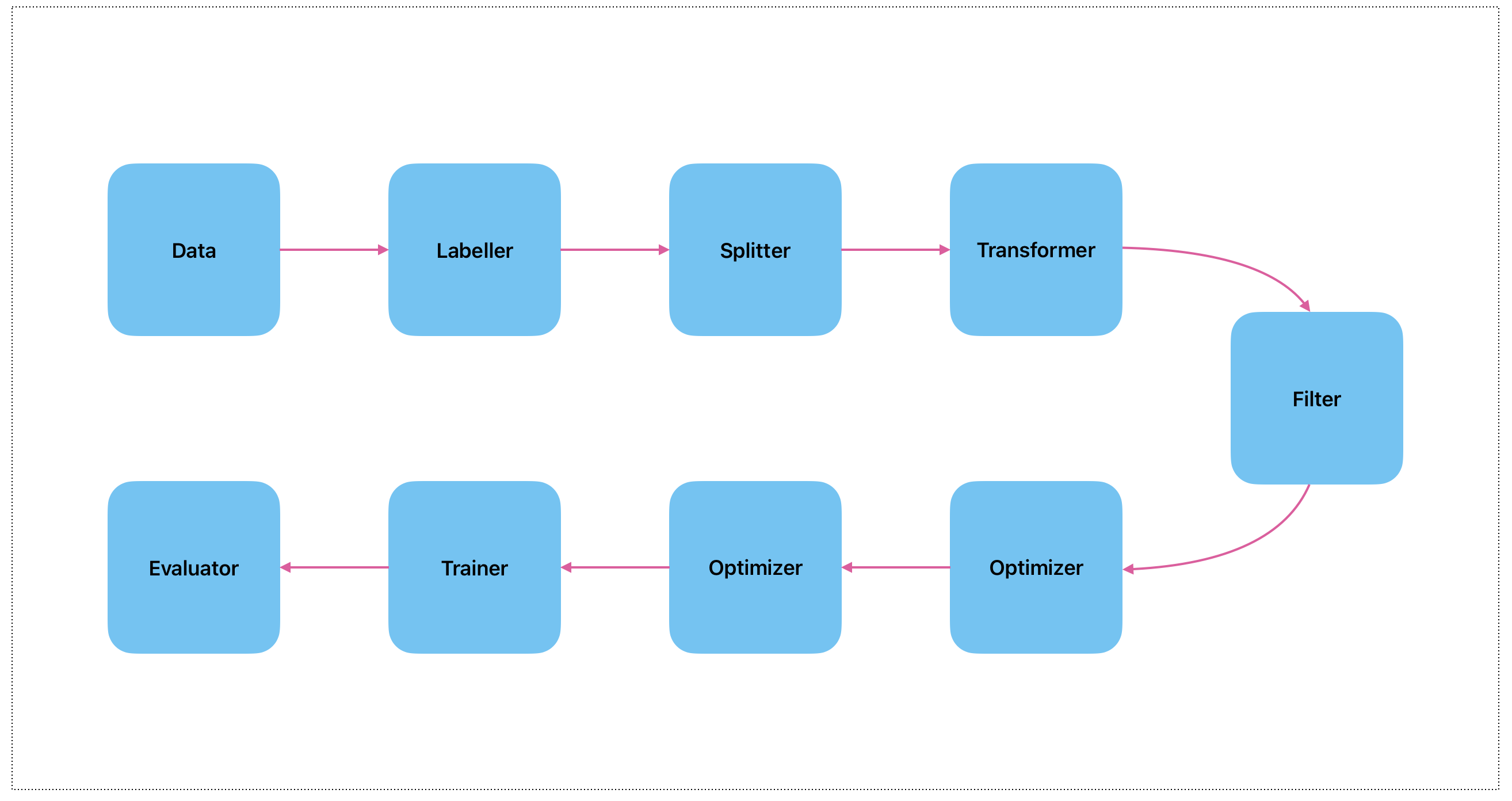
上图是一个精简版的 Machine Learning Pipeline。
Data 数据
这里的数据一般是指清洗好的数据,可能已经有了标签,也有可能需要后续的步骤去计算出标签。
Labeller 打标
有些数据是没有标签,还需要额外的逻辑去计算出标签。
Splitter 拆分
将数据拆分成为训练集和测试集。拆分的时候需要注意数据泄露的问题,避免训练集里面有某些特征会和测试集里面的数据有关系。为了避免这个问题,我们一般会按照时间去拆分。和时间没有太多关系的,我们可能会按照人口比例、性别、收入进行等比拆分。
Transformer 转换器
上面的这些特征不能够直接喂给模型,需要做一些处理,比如缩放,独热编码等操作。
Filter 过滤器
并不是所有的特征都需要,特征太多可能会导致训练时间过长。所以需要将不太重要的特征过滤掉。
Optimizer 超参优化
通过网格搜索,随机搜索,找到最优的超参,进而提升模型的效果。
Trainer 训练器
这个时候就可以进行训练,并保存模型和相关日志。
Evaluator 评估器
训练完了之后,我们还要评估模型的效果,以及与之前的模型评估。
ROC 曲线
| | Predicted |
| Actual | TN | FP |
| | FN | TP |
准确率: (TP + TN) / ALL
查准率/精确率: TP / (TP + FP)
查全率/召回率/真阳率: TP / (TP + FN)
特异度/假阳率: FP / (FP + TN)
F1 = 2 * 查准率 * 查全率 / (查准率 + 查全率)
ROC = 查全率 / 特异度