同事推荐了一个 ML 刷题的网站,正好可以拿来练手。第一道题是预测泰坦尼克号上的幸存者。
train_data = pd.read_csv("/kaggle/input/titanic/train.csv")
train_data.head()
| PassengerId | Pclass | Name | Sex | Age | SibSp | Parch | Ticket | Fare | Cabin | Embarked | |
|---|---|---|---|---|---|---|---|---|---|---|---|
| 0 | 892 | 3 | Kelly, Mr. James | male | 34.5 | 0 | 0 | 330911 | 7.8292 | NaN | Q |
| 1 | 893 | 3 | Wilkes, Mrs. James (Ellen Needs) | female | 47.0 | 1 | 0 | 363272 | 7.0000 | NaN | S |
| 2 | 894 | 2 | Myles, Mr. Thomas Francis | male | 62.0 | 0 | 0 | 240276 | 9.6875 | NaN | Q |
| 3 | 895 | 3 | Wirz, Mr. Albert | male | 27.0 | 0 | 0 | 315154 | 8.6625 | NaN | S |
| 4 | 896 | 3 | Hirvonen, Mrs. Alexander (Helga E Lindqvist) | female | 22.0 | 1 | 1 | 3101298 | 12.2875 | NaN | S |
女士优先
在英国的绅士文化里面,女士优先。如果我们将所有的女士标注为幸存,那么可以获得 80%的准确率。
women = train_data.loc[train_data.Sex == 'female']["Survived"]
rate_women = sum(women)/len(women)
print("% of women who survived:", rate_women)
men = train_data.loc[train_data.Sex == 'male']["Survived"]
rate_men = sum(men)/len(men)
print("% of men who survived:", rate_men)
y = train_data["Survived"]
X = train_data
X_train,X_test, y_train, y_test = train_test_split (X, y, test_size=0.2, stratify = y, random_state=20)
y_female = (X_test['Sex'] == 'female').values.astype(int)
y_female
accuracy = accuracy_score(y_test, y_female)
print("Accuracy:", accuracy)
# Accuracy: 0.8044692737430168
等级、性别、亲属
如果我们根据船舱等级,性别,亲属为依据,能够将准确率提升到 81.00%
from sklearn.ensemble import RandomForestClassifier
y = train_data["Survived"]
features = ["Pclass", "Sex", "SibSp", "Parch"]
X = pd.get_dummies(train_data[features])
X.head()
| Pclass | SibSp | Parch | Sex_female | Sex_male | |
|---|---|---|---|---|---|
| 0 | 3 | 1 | 0 | False | True |
| 1 | 1 | 1 | 0 | True | False |
| 2 | 3 | 0 | 0 | True | False |
| 3 | 1 | 1 | 0 | True | False |
| 4 | 3 | 0 | 0 | False | True |
X_train,X_test, y_train, y_test = train_test_split (X, y, test_size=0.2, stratify = y, random_state=20)
model = RandomForestClassifier(n_estimators=100, max_depth=5, random_state=1)
model.fit(X_train, y_train)
y_pred = model.predict(X_test)
y_pred
accuracy = accuracy_score(y_test, y_pred)
print("Accuracy:", accuracy)
# Accuracy: 0.8100558659217877
引入新的 feature Family
from sklearn.ensemble import RandomForestClassifier
y = train_data["Survived"]
features = ["Pclass", "Sex", "SibSp", "Parch"]
X = pd.get_dummies(train_data[features])
X.head()
| Pclass | SibSp | Parch | Sex_female | Sex_male | |
|---|---|---|---|---|---|
| 0 | 3 | 1 | 0 | False | True |
| 1 | 1 | 1 | 0 | True | False |
| 2 | 3 | 0 | 0 | True | False |
| 3 | 1 | 1 | 0 | True | False |
| 4 | 3 | 0 | 0 | False | True |
X_train,X_test, y_train, y_test = train_test_split (X, y, test_size=0.2, stratify = y, random_state=20)
X_train['Fam'] = X_train['SibSp'] + X_train['Parch'] + 1
X_test['Fam'] = X_test['SibSp'] + X_test['Parch'] + 1
X_train.head()
model = RandomForestClassifier(n_estimators=100, max_depth=5, random_state=1)
model.fit(X_train, y_train)
y_pred = model.predict(X_test)
y_pred
accuracy = accuracy_score(y_test, y_pred)
print("Accuracy:", accuracy)
# Accuracy: 0.8156424581005587
老幼优先
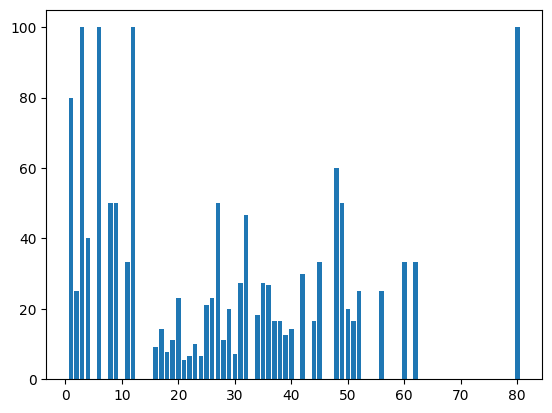
通过下面的数据可以观察到,儿童和老年的存活率比较高,我们断言当时女人、老人、儿童优先得到了救援。
male_train_df = train_data[train_data['Sex'] == 'male']
import matplotlib.pyplot as plt
male_train_df['Age'] = np.ceil(male_train_df['Age'])
survived_percent_by_age = (male_train_df.groupby('Age')['Survived'].mean() * 100).round(2)
plt.bar(survived_percent_by_age.index, survived_percent_by_age.values)
plt.show()
from sklearn.ensemble import RandomForestClassifier
y = train_data["Survived"]
X = train_data[["Pclass", "Sex", "SibSp", "Parch", "Age"]]
X = pd.get_dummies(X)
# children
X['is_child'] = X['Age'] <= 16
X['is_old'] = X['Age'] >= 60
X = X.drop(columns=['Age']).astype(int)
X.head()
X_train,X_test, y_train, y_test = train_test_split (X, y, test_size=0.2, stratify = y, random_state=20)
model = RandomForestClassifier(n_estimators=100, max_depth=5, random_state=1)
model.fit(X_train, y_train)
y_pred = model.predict(X_test)
y_pred
accuracy = accuracy_score(y_test, y_pred)
print("Accuracy:", accuracy)
# Accuracy: 0.8212290502793296
提交作业
提交作业,得到了 0.7799 的准确率。
df_test = test_data.copy()
X = df_test[["Pclass", "Sex", "SibSp", "Parch", "Age"]]
X = pd.get_dummies(X)
# children
X['is_child'] = X['Age'] <= 16
X['is_old'] = X['Age'] >= 60
X = X.drop(columns=['Age']).astype(int)
X.head()
y_pred = model.predict(X)
output = pd.DataFrame({'PassengerId': df_test.PassengerId, 'Survived': y_pred})
output.to_csv('submission.csv', index=False)
print("Your submission was successfully saved!")