- 创建 service account
- Build OSS image
- Build ML image
- 创建 Airflow connection
- 架构图
- 创建 KubernetesPodOperator
创建 service account
首先需要创建一个 service account airflow,直接kuberctl apply -f .创建资源。
apiVersion: rbac.authorization.k8s.io/v1
kind: Role
metadata:
name: airflow-role
namespace: airflow
rules:
- apiGroups:
- ""
resources:
- pods
verbs:
- get
- list
- watch
- create
- delete
- update
- patch
- apiGroups:
- ""
resources:
- pods/log
verbs:
- get
- list
- watch
- apiGroups:
- ""
resources:
- pods/exec
verbs:
- get
- list
- create
- delete
- watch
- apiGroups:
- ""
resources:
- pods/proxy
verbs:
- create
- delete
- get
- patch
- update
- apiGroups:
- ""
resources:
- events
verbs:
- list
---
kind: RoleBinding
apiVersion: rbac.authorization.k8s.io/v1
metadata:
name: airflow-rolebinding
namespace: airflow
labels:
tier: airflow
roleRef:
apiGroup: rbac.authorization.k8s.io
kind: Role
name: airflow-role
subjects:
- kind: ServiceAccount
name: airflow
namespace: airflow
---
kind: ServiceAccount
apiVersion: v1
metadata:
name: airflow
namespace: airflow
labels:
tier: airflow
Build OSS image
FROM python:3.10.13-slim
RUN pip install oss2 --no-cache-dir
COPY oss_download.py .
# oss_download.py
import os
import json
import base64
import oss2
from oss2.credentials import EnvironmentVariableCredentialsProvider
tuples_base64 = os.environ.get('PROCESSING_INPUTS')
tuples_json = base64.b64decode(tuples_base64).decode()
tuples = json.loads(tuples_json)
auth = oss2.ProviderAuth(EnvironmentVariableCredentialsProvider())
bucket_name = os.environ.get('OSS-BUCKET-NAME')
bucket = oss2.Bucket(auth, 'https://oss-cn-beijing-internal.aliyuncs.com', bucket_name)
for t in tuples:
filekey = t['source'].replace(f'oss://{bucket_name}/', '')
if bucket.object_exists(filekey):
filename = os.path.basename(filekey)
destination = os.path.join(t['destination'], filename)
print(f"downloading files from oss {filekey} to {destination}")
os.makedirs(os.path.dirname(destination), exist_ok=True)
bucket.get_object_to_file(filekey, destination)
else:
for k in oss2.ObjectIterator(bucket, prefix=filekey):
filename = os.path.basename(k.key)
destination = os.path.join(t['destination'], filename)
print(f"downloading files from oss {k.key} to {destination}")
os.makedirs(os.path.dirname(destination), exist_ok=True)
bucket.get_object_to_file(k.key, destination)
Build ML image
FROM python:3.10.13-slim
RUN apt-get update && apt-get install -y tree
RUN pip install pandas numpy xgboost scikit-learn pyarrow fastparquet --no-cache-dir
RUN pip install matplotlib oss2 dill openpyxl simplejson et-xmlfile --no-cache-dir
COPY oss_upload.py .
# oss_upload.py
import os
import oss2
from oss2.credentials import EnvironmentVariableCredentialsProvider
oss_step_path = os.environ.get('PROCESSING_OUTPUT_PATH')
bucket_name = os.environ.get('OSS-BUCKET-NAME')
output_directory = '/opt/ml/processing/output'
auth = oss2.ProviderAuth(EnvironmentVariableCredentialsProvider())
bucket = oss2.Bucket(auth, 'https://oss-cn-beijing-internal.aliyuncs.com', bucket_name)
for root, dirs, files in os.walk(output_directory):
for file in files:
local_path = os.path.join(root, file)
relative_path = os.path.relpath(local_path, output_directory)
oss_file_key = os.path.join(oss_step_path, relative_path)
print(f"upload file from {local_path} to {oss_file_key}")
bucket.put_object_from_file(oss_file_key, local_path)
创建 Airflow connection
在新版本的 Airflow apache/airflow:2.8.1-python3.10镜像中,已经安装好了apache-airflow-providers-cncf-kubernetes。如果 Airflow 的镜像中没有,需要额外安装一次。
pip install apache-airflow-providers-cncf-kubernetes
然后创建一个 Kubernetes connection, 勾选in_cluster即可。这样勾选的意思,Airflow 会选用 Pod 里面 serviceaccount 的权限,去调用 Kubernetes API。
如果是本地开发,就需要一个空白的 connection,它就会用当前用户的~/.kube/config文件。
架构图
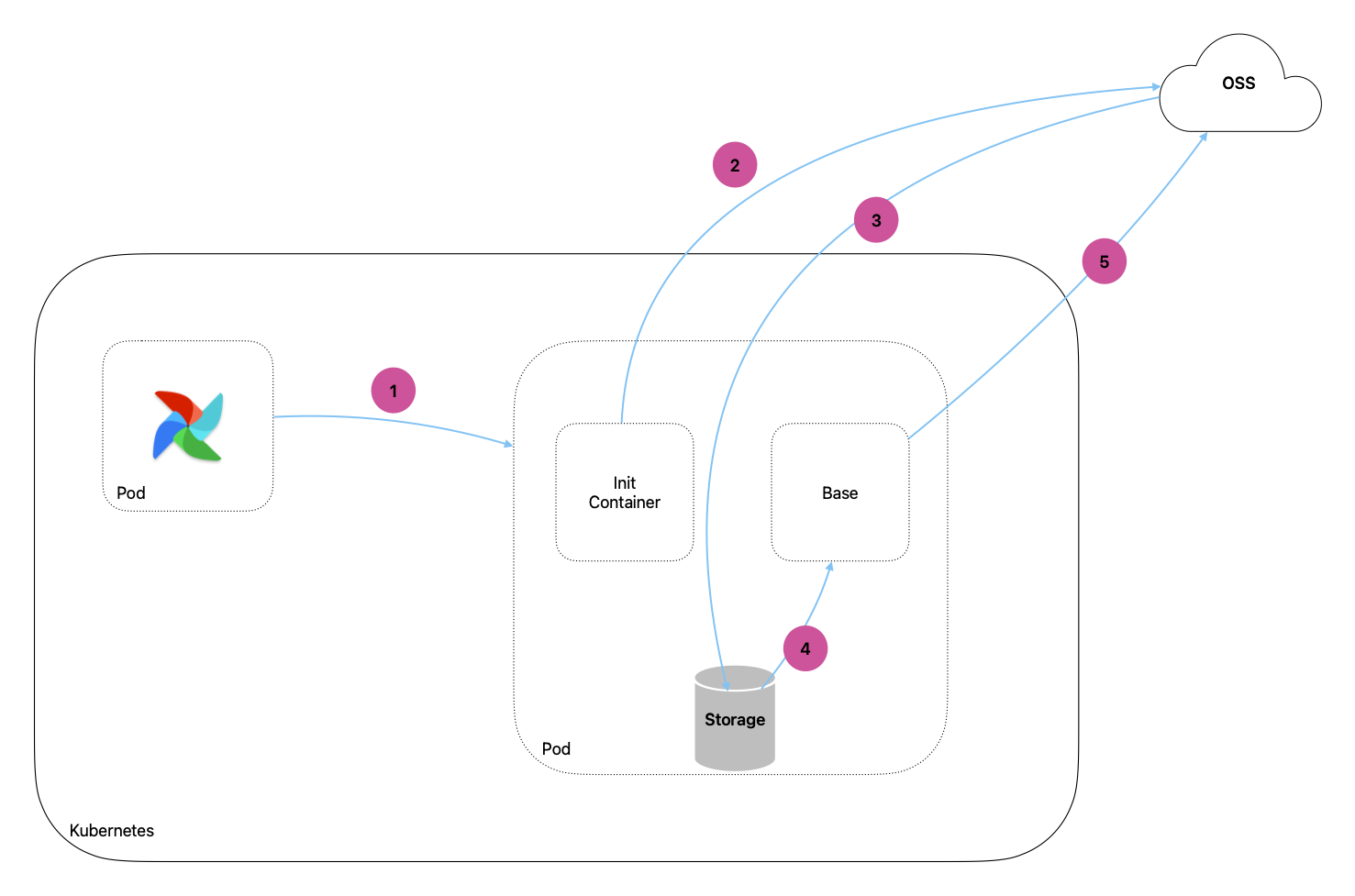
- Airflow 会通过 KubernetesPodOperator 拉起一个 Pod 在执行任务。
- Pod 里面的 init_container 会去 OSS 拉取需要的文件
- 文件会被下载到 Volume 里面,共享给 base container。
- base container 会根据下载好的资源,执行 python 脚本
- 最后将
/opt/ml/processing/output里面的产物上传到 OSS,供下一步使用。
创建 KubernetesPodOperator
Airflow 提供了 KubernetesPodOperator,可以按照官网的例子,就可以使用了。
这里提一下几个需要注意的地方。
- Airflow 要调 Kubernetes API,就需要先授权。本地会使用
~/.kube/config文件里面 context 来访问 API,Kubernete 的 Pod 里面就需要在 Deployment 里面指定第一步创建好的 service account - 需要下载的文件在
config里面指定好了,但是需要告诉init_container所有资源的 OSS 地址。这里用 base64 encode 一次,当做环境变量PROCESSING_INPUTS传入init_container。 - base 容器里面需要执行多个命令,这里通过
bash -cx "python code.py && python oss_upload.py"来实现。 - Operator 里面不需要设置
do_xcom_push,因为整个函数会被@task修饰一次,直接就会执行。所以在这个函数里面可以随意的return值,会被传入 xcom,传给下一步。
def kubernetes_script_processor(config, step_name, oss_paths, context):
step_config = config['steps'][step_name]
oss_bucket = config['bucket_name']
_, _, job_oss_path = oss_paths['job_oss_path'].replace("oss://", "").partition('/')
oss_output_path = os.path.join(job_oss_path, step_name)
base_job_name = f'{dag_id}-{step_name}'
code_file_path = os.path.join(dag_file_path, step_config['code_path'])
code_file_name = os.path.basename(code_file_path)
oss_code_file_key = os.path.join(oss_output_path, step_config['code_path'])
bucket(bucket_name=oss_bucket).put_object_from_file(oss_code_file_key, code_file_path)
inputs = [
ProcessingInput(
name='config',
source=oss_paths['config_file_path'],
destination=step_config['config_destination']
),
ProcessingInput(
name='code',
source=oss_code_file_key,
destination='/opt/ml/processing/input/code'
)
]
if 'package_destination' in step_config:
package_destination = step_config['package_destination']
if package_destination is not None:
inputs.append(
ProcessingInput(
name='package',
source=config['package_path'],
destination=package_destination
)
)
if 'health_report_destination' in step_config:
package_destination = step_config['health_report_destination']
print('health_report_destination##', package_destination, package_destination)
if package_destination is not None:
inputs.append(
ProcessingInput(
name='health_report',
source=step_config['health_report_path'],
destination=package_destination
)
)
for input_name, input_destination in step_config['inputs'].items():
if input_name == 'hyperparams' and 'hyperparams' not in oss_paths.keys():
continue
input_data_path = oss_paths[input_name]
inputs.append(
ProcessingInput(
name=input_name,
source=input_data_path,
destination=input_destination['destination']
)
)
inputs_base64 = base64.b64encode(json.dumps([x._asdict() for x in inputs]).encode()).decode()
# build the init_containers before the real container starts
oss_column = k8s.V1Volume(
name="oss-volume",
empty_dir=k8s.V1EmptyDirVolumeSource()
)
oss_container_volume_mounts = [
k8s.V1VolumeMount(mount_path="/opt/ml/processing/input", name="oss-volume", sub_path=None, read_only=False)
]
environments = [
k8s.V1EnvVar(name="PROCESSING_INPUTS", value=inputs_base64),
k8s.V1EnvVar(name="PROCESSING_OUTPUT_PATH", value=oss_output_path)
]
init_container = k8s.V1Container(
name="init-container",
image="ml-oss:0.0.8",
env=environments,
env_from=[k8s.V1EnvFromSource(secret_ref=k8s.V1SecretEnvSource(name='airflow-secrets'))],
volume_mounts=oss_container_volume_mounts,
command=["python"],
args=["oss_download.py"]
)
# start the pod
volume_mount = k8s.V1VolumeMount(
name="oss-volume", mount_path="/opt/ml/processing/input", sub_path=None, read_only=True
)
k = KubernetesPodOperator(
namespace="airflow",
image="ml-xgboost:0.0.6",
# cmds=["bash", "-c", "--"],
# arguments=["while true; do sleep 30; done;"],
cmds=["bash", "-cx"],
arguments=[f"tree /opt/ml/processing/ && python {os.path.join('/opt/ml/processing/input/code', code_file_name)} && python oss_upload.py"],
env_vars=environments,
env_from=[k8s.V1EnvFromSource(secret_ref=k8s.V1SecretEnvSource(name='airflow-secrets'))],
volumes=[oss_column],
volume_mounts=[volume_mount],
name=f"{dag_id}-pod",
task_id=base_job_name,
on_finish_action="delete_pod",
init_containers=[init_container],
image_pull_secrets=[k8s.V1LocalObjectReference("your-cr-credentials")],
kubernetes_conn_id='kuberneter-conn',
service_account_name='airflow'
)
k.execute(context=context)
xcom_outputs = oss_paths
for output_name in step_config['outputs'].keys():
xcom_outputs.update({output_name: os.path.join(f'oss://{oss_bucket}', oss_output_path, output_name)})
return xcom_outputs