Kubernetes Service
Kubernetes 里面为什么要有 service
因为 Pod 是动态伸缩的,所以它们的 IP 是不固定的,为了解决这个问题,我们需要在 Pod 前面加个代理,service 就出现了。对于 Ingress 而言,service 的 IP 是一致不变的,所以 Ingress 这一套就不用动了。动的只需要是 Service 背后的 pods。
Service 是如何访问到 Pods 的
kube-proxy。 如果看过 clash 源码的童鞋可能知道,clash 的背后其实就是设置了很多 iptables 规则,去进行包的转发。同样,在 Kubernetes 里面,kube-proxy 也是通过 iptables/ipvs 来实现代理,从而实现 service 到 pod 消息的转发。
为什么现在几乎都用 ipvs 了
iptables 本来是设计给防火墙用的,不是天生用来做这种负载均衡的事情。当 pods 数量超过 1000 的时候,iptables 里面的规则就非常多,即使在内核态工作,也扛不住这么玩。举个例子,单纯让一个 service 转发到 3 个 pods,就可能写上超过 7 条的规则,而且还是一个规则套另外一个规则。
此外,整个规则是放在一个链表里面的,如果要查询就只能够 table scan,效率很低。
ipvs 原生就是做负载均衡的,和 iptables 一样工作在 OSI 网络第四层(对比 Nginx 是工作 OSI 网络第 7 层,支持域名级别的负载均衡)。对于一个 service 转发到 2 个 pods,就只需要 2 条记录就行了。此外,ipvs 背后使用 hash 表,加快了查询速度。
题外话。网上问到为什么 ipvs 比 iptables 快的时候,大家简单归结为 ipvs 用的是 hash 表,查询速度快;或者说 ipvs 工作在内核态,比 iptables 快,这些都是不完整的。ipvs 和 iptables 都工作在内核态,都是 OSI 第四层,就算 iptables 把数据结构换成 hash 表,也会比 ipvs 慢,因为 iptables 的设计上会把规则一层一层套上去,导致规则太多。
如何在 node 上访问 service
试试 <svc-name>.<namespace>.svc.cluster.local就可以通过 service 访问到背后的 pods
Service 类型 ClusterIP
ClusterIP 是能够在集群内部互相访问的模式,一般 IP 是 192.168.X.X。这种模式不支持从外部直接访问,但可以用 port-forward 来访问。
Service 类型 NodePort
基于上面的 ClusterIP 模式,在集群的每个 Node 上都开启一个端口,通过端口访问到对应的 Pod。
Service 类型 LoadBalancer
依托公有云上的 Kubernetes 集群,这种模式下会自动创建一个 LoadBalancer 来负载背后的 Pod。这个是基于 4 层协议,且每个 service 都会有一个负载均衡。
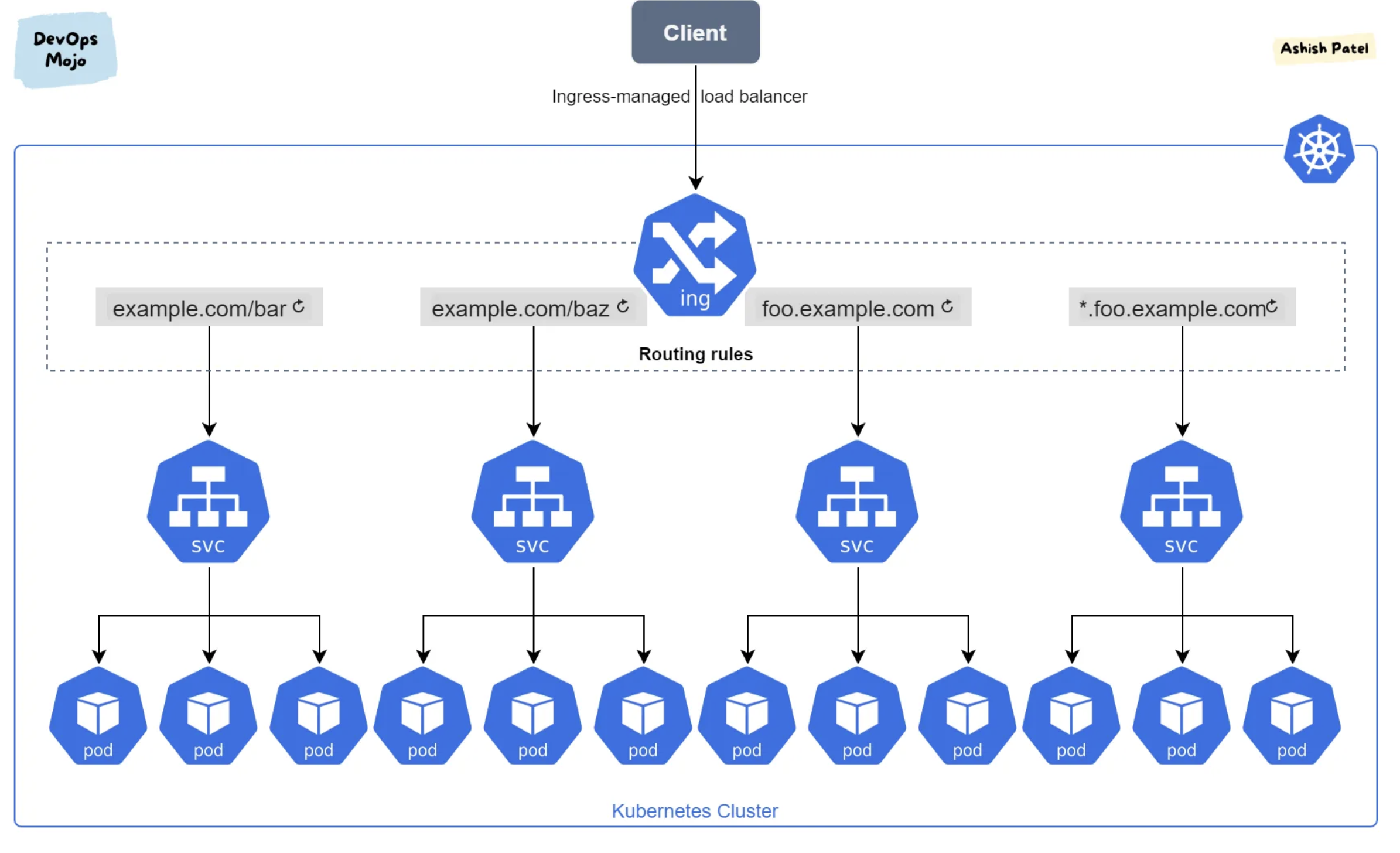
Ingress Controller
LoadBalancer 虽然好,但是破浪费,一个 Service 需要一个 LoadBalancer。Ingress Controller 就支持多个 service 的反向代理,支持 7 层协议。这样,就一个 Ingress Controller,就可以访问不同的 Service 了。