借着上次的机会,自己打造了一个个人版的小爱同学,自己对 Bert 也感了兴趣。
那为什么是 Bert,而不用 LLM?
NLP 的历史
每个人对于 Transformer 和 Bert 的解读都不一样,3Blue1Brown 居然都还有视频来解释什么是 transformer。但如果是现在去回顾历史,就会发现这些东西的演变真的很有意思。
要介绍 Transformer,就不得不提到 NLP 的发展过程。
最初的时候,为了解决机器翻译的问题,人们提出了 seq2seq 模型,即翻译一段句子。到了 2014 年,两篇论文12介绍了基于神经网络,实现的机器翻译。
encoder 和 decoder 的组合,往往都是 RNN 循环神经网络,其大致实现如下:
- 每次读入一个单词,embedding 之后通过 encoder 转换成为上下文(可以认为是理解了整个句子或者 Hidden state),直到读完整个句子。
- 传入最后生成的 hidden state,再通过 decoder 翻译成另外一个语言,每次蹦一个词出来,依次循环。
基于 RNN 的机器翻译,中间的 context 上下文非常关键,但也成了瓶颈,尤其是在长句子的理解上。2014 年的另外两篇论文34提出了注意力机制,有效地让模型更加关注每个单词。
首先,hidden state 不再是最后一层,而是针对每个单词都有一个 hidden state。 其次,针对每个 hidden state,进行评分和 softmax,进而计算出相应输出。
2017 年,一篇Attention is All you Need的论文横空出世,Transformer 诞生了。上面基于 RNN 的模型,效果是不错了,但是训练速度却很慢。Transformer 通过实现并行计算,加速了模型的训练速度。Transformer 由多个 Encoder 和多个 Decoder 叠加而成,不仅针对上下文引入了注意力机制,还引入了多头注意力机制,效果超过了传统的 RNN 机器翻译模型。
2018 年,在前面诸多成果的基础上,谷歌推出了 Bert,成为 NLP 的跨时代产品。
Bert 能干什么?
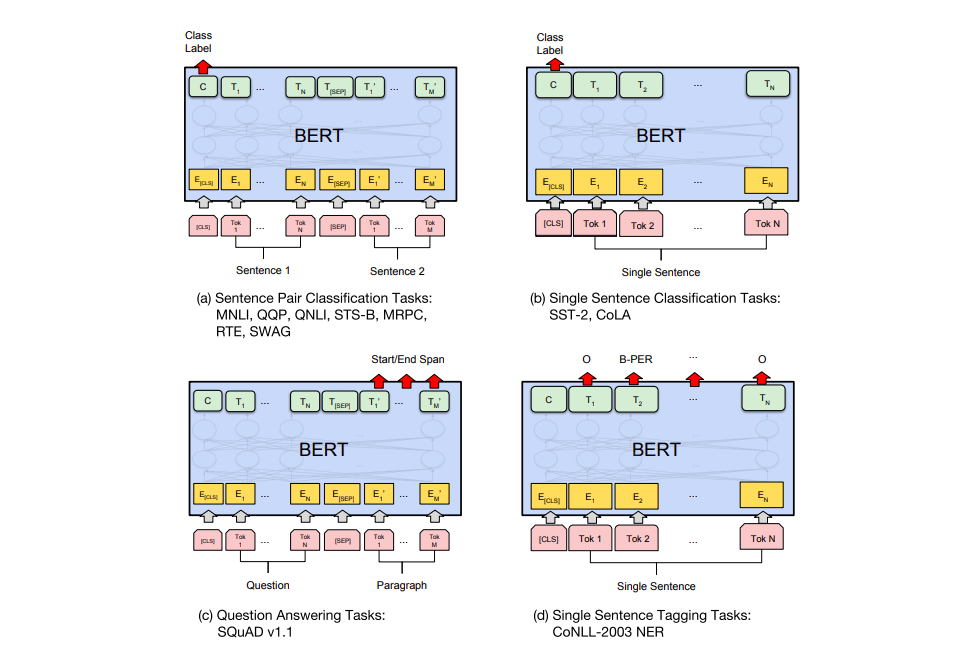
上面这幅图解释了 Bert 可以做一些常见的 NLP 任务,比如分类,完形填空,两个句子是否是关联,以及问答系统。
为什么我不用 LLM
慢和准确。
LLM 要么就是直接调用 LLM 厂商的 API,要么就是自己部署开源 LLM 的 API,无论哪种,都不可避免的发现 LLM 会比较慢。尤其是在 LLM 识别完意图和传给下一步的参数(槽位)的时候,会更加明显。对比 Bert,常规的 CPU 部署几乎在一秒内就可以完成意图识别,已经对应的任务调用。
在准确性上,我可以通过增加微调迭代次数,提供更多的训练数据,从而可以提升效果。但是对于 LLM,我只能够通过尝试各种提示词组合,但是上下文太长又会导致 LLM 失去精度。而 RAG 对我来说就是开卷考试,干着类似于 elasticsearch+LLM 转成自然语言的事情,并不是什么有意义的事情。