Argo 家除了大名鼎鼎的 ArgoCD,还有一个非常强大的产品叫 Argo Workflow。我知道这个产品,其实是因为 Kubeflow(一款基于 Kubernetes 的机器学习平台)。后来发现 Kubeflow Pipeline 的底层编排引擎其实就是 Argo Workflow,这极大引起了我的兴趣。
简单来说,Argo Workflow 是一个开源的、云原生的容器编排引擎,专门用于在 Kubernetes 上运行并行任务(Workflow)。它的每一个步骤(Step)都是一个独立的容器,非常适合用来做数据处理、机器学习流水线或者 CI/CD。
本文将带你快速上手 Argo Workflow,从安装到运行第一个 Hello World,再到理解参数与文件的传递。
安装 Argo Workflow
为了快速体验,我们可以按照官网的 Quick Start,在本地的 Kubernetes 集群(如 Docker Desktop, OrbStack, Minikube 或 Kind)中部署 Argo Workflow。
部署完成后,我们可以通过 Port Forward 访问 Argo 的 UI 界面,准备开始我们的第一个工作流。
运行 Hello World
我们先从最简单的 Hello World 开始。Argo Workflow 的核心是 YAML 定义,下面是一个基础的 Workflow 配置:
apiVersion: argoproj.io/v1alpha1
kind: Workflow
metadata:
generateName: hello-world-
labels:
workflows.argoproj.io/archive-strategy: "false"
annotations:
workflows.argoproj.io/description: |
This is a simple hello world example.
spec:
serviceAccountName: default
entrypoint: hello-world
templates:
- name: hello-world
container:
image: busybox
command: [echo]
args: ["hello world"]
这个 Workflow 非常直白:入口点是 hello-world 模板,它会启动一个 busybox 容器并执行 echo "hello world"。
将上述内容保存为文件或直接使用官方链接,通过 argo submit 命令提交到集群:
argo submit -n argo --watch https://raw.githubusercontent.com/argoproj/argo-workflows/main/examples/hello-world.yaml
加上 --watch 参数后,我们可以在命令行实时看到工作流的执行状态和最终结果:
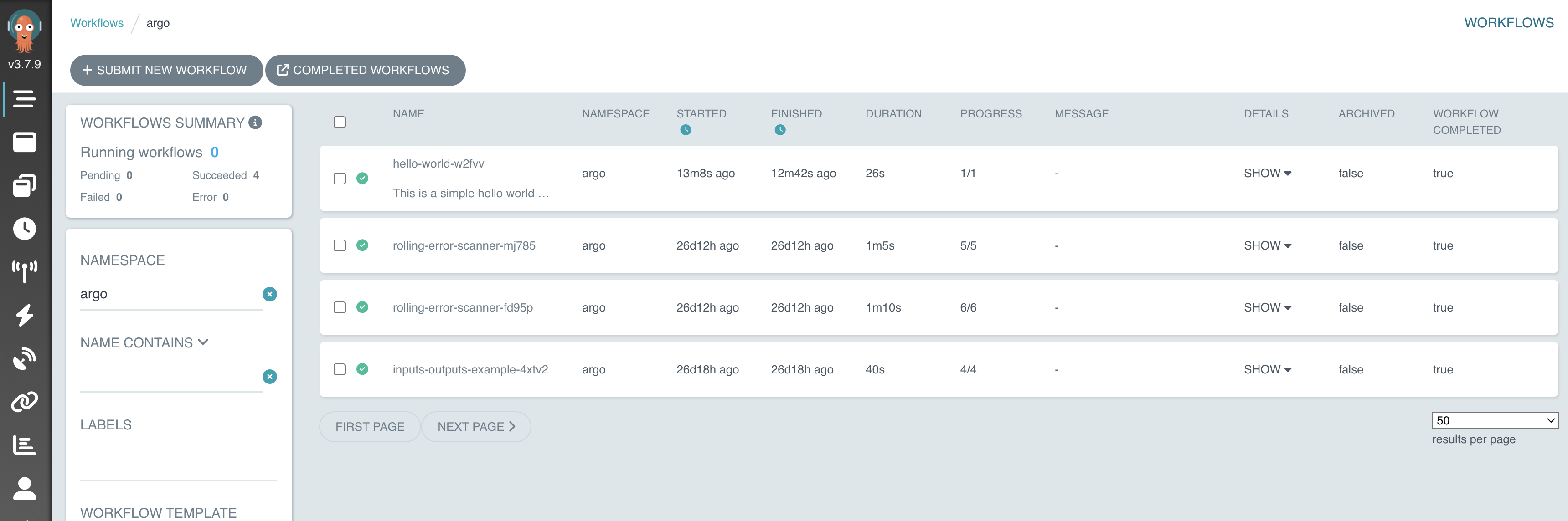
Name: hello-world-w2fvv
Namespace: argo
ServiceAccount: unset (will run with the default ServiceAccount)
Status: Succeeded
Conditions:
PodRunning False
Completed True
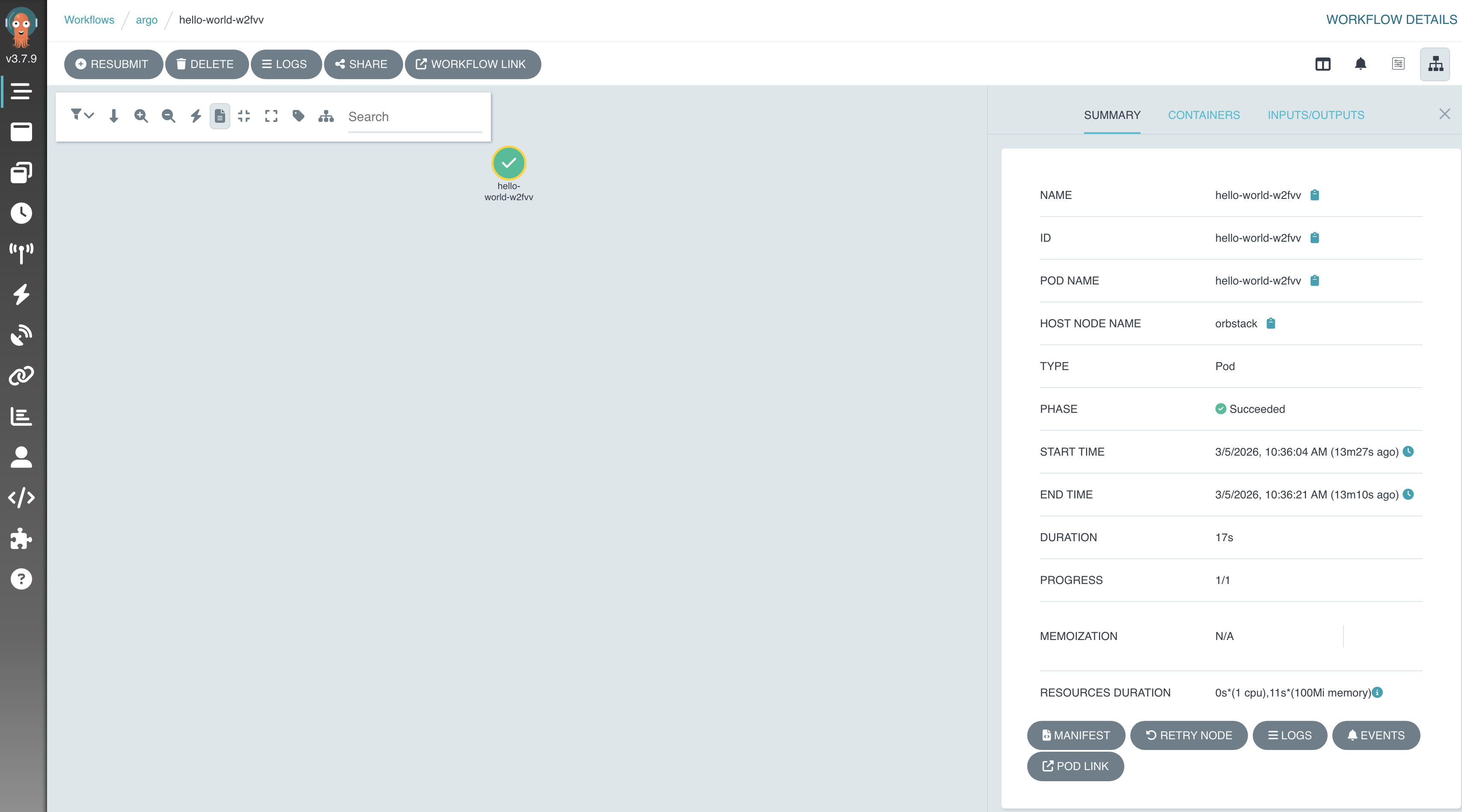
Created: Thu Mar 05 10:36:04 +0800 (26 seconds ago)
Started: Thu Mar 05 10:36:04 +0800 (26 seconds ago)
Finished: Thu Mar 05 10:36:30 +0800 (now)
Duration: 26 seconds
Progress: 1/1
ResourcesDuration: 0s*(1 cpu),11s*(100Mi memory)
STEP TEMPLATE PODNAME DURATION MESSAGE
✔ hello-world-w2fvv hello-world hello-world-w2fvv 17s
除了命令行,Argo 提供了非常直观的 Web UI。在 UI 中,我们可以清晰地看到 Workflow 的执行节点(虽然这里只有一个节点):
点击进入 Summary 界面,还能查看到详细的耗时、容器状态以及资源消耗等信息:
日志与产物管理 (Log & Artifacts)
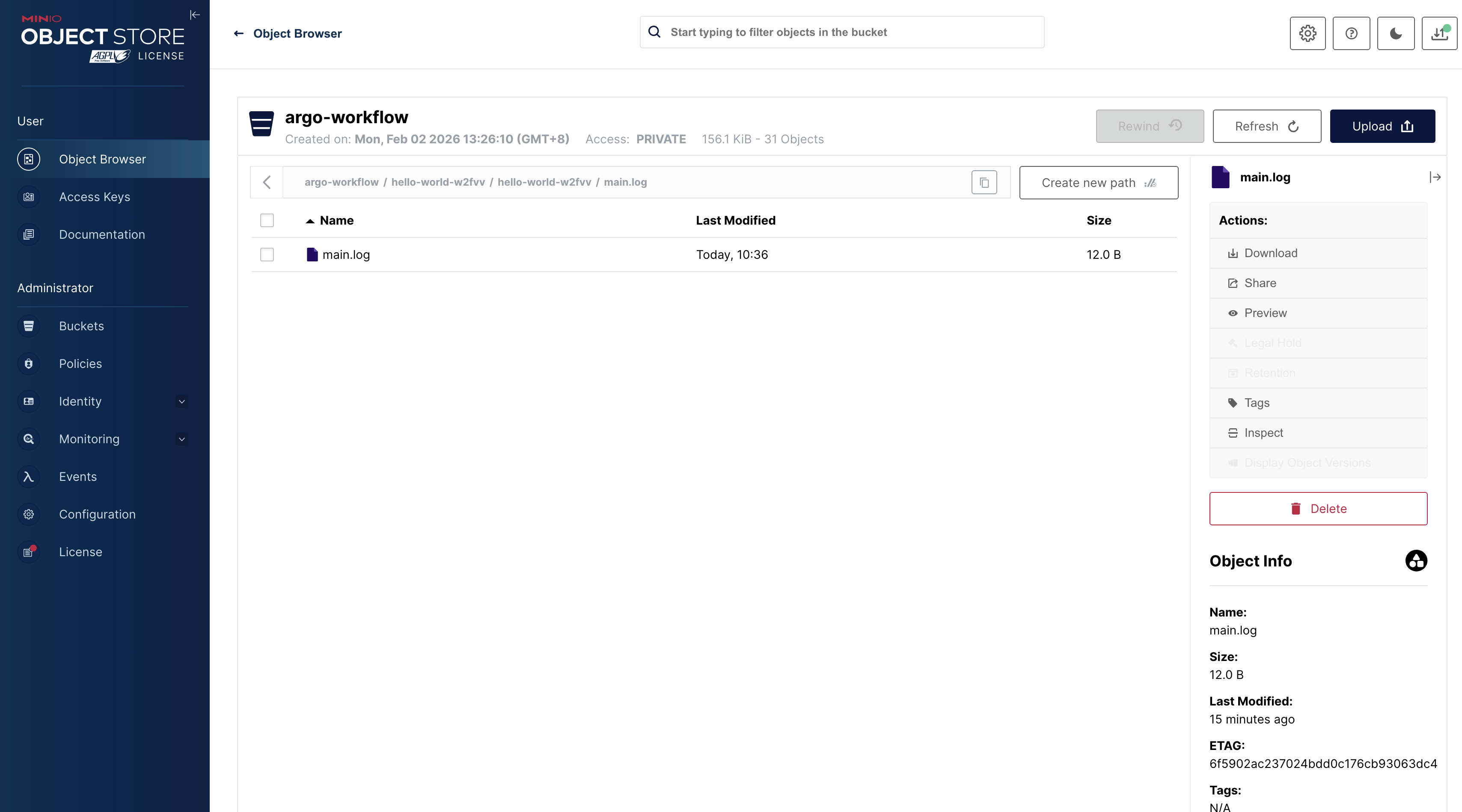
在实际的生产环境中,任务的日志和输出文件(Artifacts)通常需要持久化存储。Argo Workflow 原生支持将这些数据归档到 S3 兼容的对象存储中(例如 MinIO)。
配置好 Artifact Repository 后,我们可以在 MinIO 的 Bucket 中直接看到 Argo 自动上传的日志文件和产物压缩包,这为排查问题和数据流转提供了极大的便利:
进阶:Input & Output 传递
真实的业务流水线往往是由多个相互依赖的步骤组成的,这就涉及到步骤之间的数据传递。Argo Workflow 支持两种主要的数据传递方式:
- Parameters (参数):适合传递简单的字符串或数值。
- Artifacts (产物):适合传递大文件或目录。
下面这个例子展示了如何在一个 DAG(有向无环图)中,实现参数和文件的生产与消费:
apiVersion: argoproj.io/v1alpha1
kind: Workflow
metadata:
generateName: inputs-outputs-example-
spec:
entrypoint: main
templates:
- name: main
dag:
tasks:
# 1. 产生 Output Parameter
- name: producer-param
template: generate-parameter
# 2. 消费 Input Parameter (来自上一步的 output)
- name: consumer-param
dependencies: [producer-param]
template: print-message
arguments:
parameters:
- name: message
value: ""
# 3. 产生 Output Artifact
- name: producer-artifact
template: generate-artifact
# 4. 消费 Input Artifact (来自上一步的 output)
- name: consumer-artifact
dependencies: [producer-artifact]
template: print-artifact-content
arguments:
artifacts:
- name: text-file
from: ""
# ---------------------------------------------------------
# 定义输出 Parameter 的模板
# ---------------------------------------------------------
- name: generate-parameter
container:
image: alpine:latest
command: [sh, -c]
# 将内容写入文件,然后通过 valueFrom 读取为 Parameter
args: ["echo 'Hello from Upstream' > /tmp/hello.txt"]
outputs:
parameters:
- name: hello-param
valueFrom:
path: /tmp/hello.txt
# ---------------------------------------------------------
# 定义输入 Parameter 的模板
# ---------------------------------------------------------
- name: print-message
inputs:
parameters:
- name: message # 定义参数名
container:
image: alpine:latest
command: [sh, -c]
# 使用 引用
args: ["echo Received message: "]
# ---------------------------------------------------------
# 定义输出 Artifact 的模板
# ---------------------------------------------------------
- name: generate-artifact
container:
image: alpine:latest
command: [sh, -c]
args: ["echo 'This is file content' > /tmp/output_file.txt"]
outputs:
artifacts:
- name: hello-art
path: /tmp/output_file.txt
# ---------------------------------------------------------
# 定义输入 Artifact 的模板
# ---------------------------------------------------------
- name: print-artifact-content
inputs:
artifacts:
- name: text-file
path: /tmp/input_file.txt # Argo 会自动将 artifact 提取到这个路径
container:
image: alpine:latest
command: [sh, -c]
args: ["cat /tmp/input_file.txt"]
提交这个 Workflow:
argo submit -n argo --watch inputs-outputs-example.yaml
执行结果如下,可以看到 4 个 Task 按照依赖关系依次执行完毕:
Name: inputs-outputs-example-8xd9v
Namespace: argo
ServiceAccount: unset (will run with the default ServiceAccount)
Status: Succeeded
Conditions:
PodRunning False
Completed True
Created: Thu Mar 05 10:54:16 +0800 (40 seconds ago)
Started: Thu Mar 05 10:54:16 +0800 (40 seconds ago)
Finished: Thu Mar 05 10:54:56 +0800 (now)
Duration: 40 seconds
Progress: 4/4
ResourcesDuration: 31s*(100Mi memory),0s*(1 cpu)
STEP TEMPLATE PODNAME DURATION MESSAGE
✔ inputs-outputs-example-8xd9v main
├─✔ producer-artifact generate-artifact inputs-outputs-example-8xd9v-generate-artifact-4205975147 18s
├─✔ producer-param generate-parameter inputs-outputs-example-8xd9v-generate-parameter-2137711306 18s
├─✔ consumer-artifact print-artifact-content inputs-outputs-example-8xd9v-print-artifact-content-3511299333 8s
└─✔ consumer-param print-message inputs-outputs-example-8xd9v-print-message-2377990840 8s
在 Argo UI 中,DAG 的依赖关系一目了然。consumer 节点会等待对应的 producer 节点完成后才开始执行:
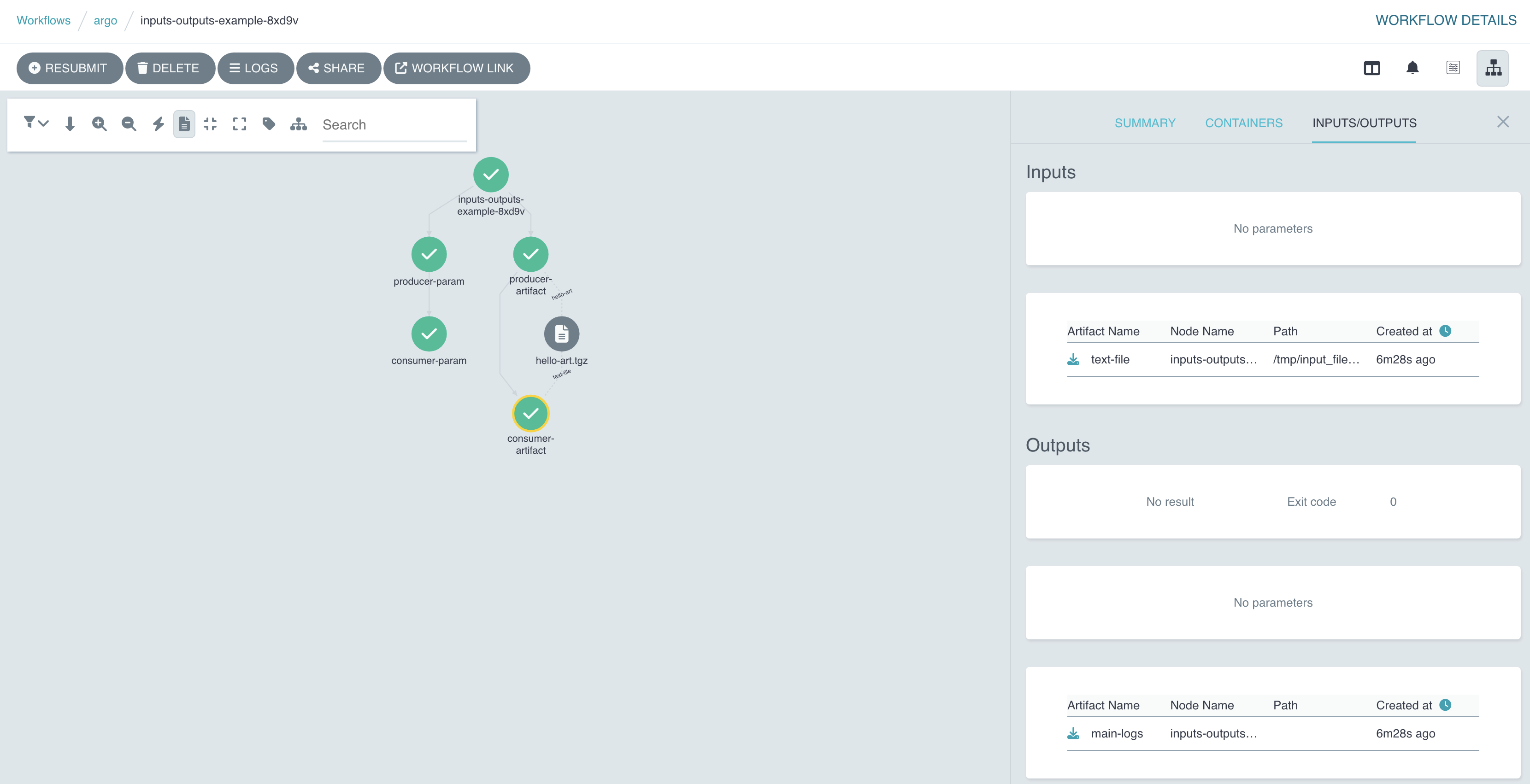
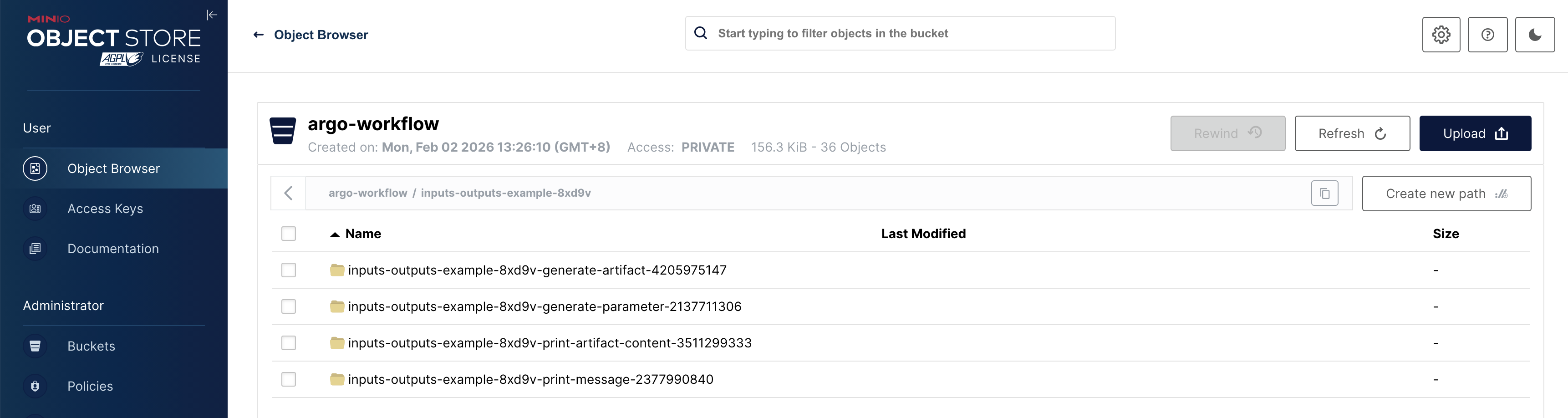
同时,如果你去查看 MinIO,会发现 producer-artifact 步骤产生的文件已经被打包上传,随后又被下载并解压到了 consumer-artifact 步骤的容器中,整个过程对用户来说是透明的:
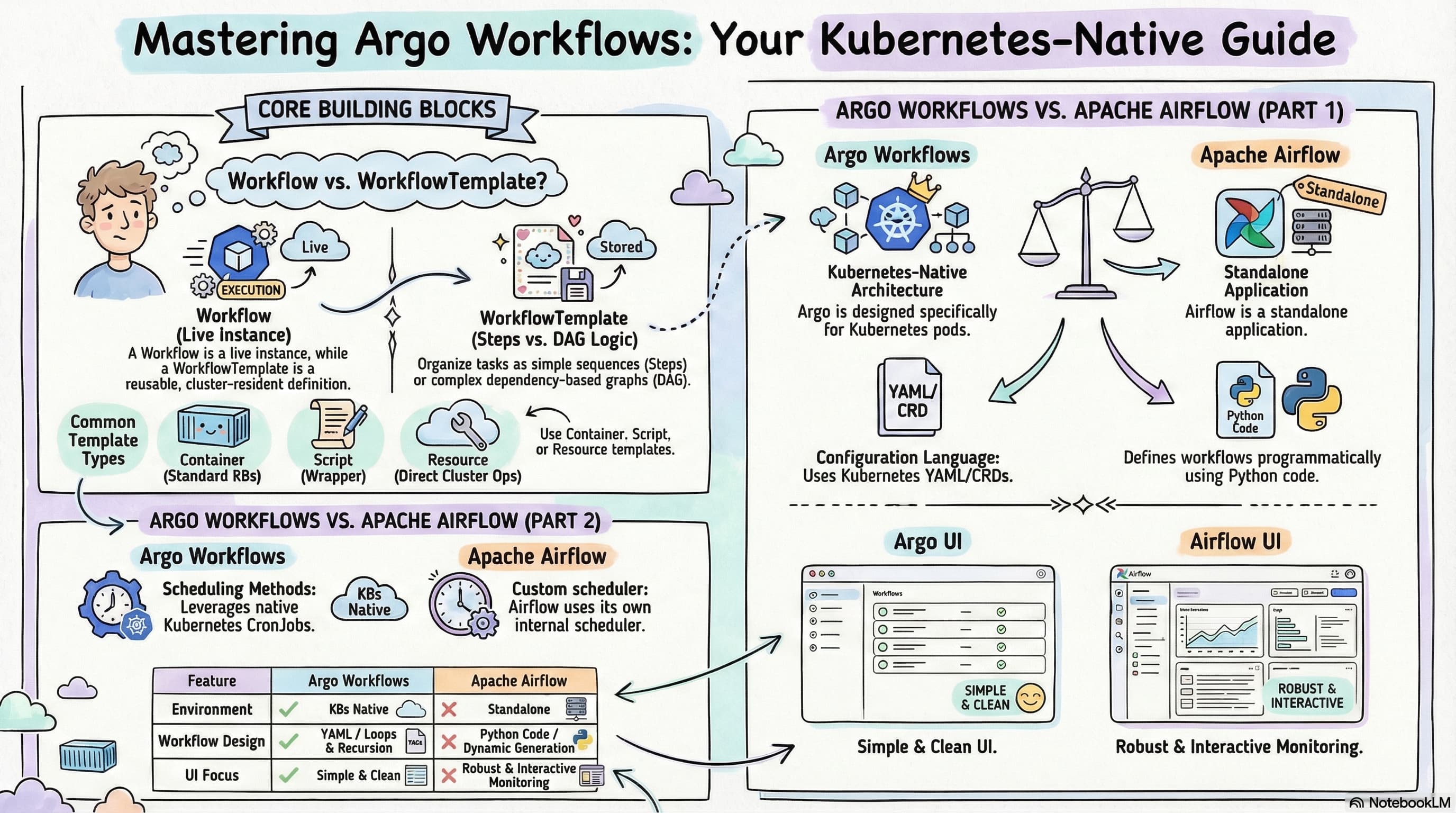
选型:Argo Workflow vs Apache Airflow
在提到工作流引擎时,很多人会自然地想到老牌的 Apache Airflow。它们两者定位不同,各有千秋,下面是它们的几个核心区别:
1. 架构基础(Kubernetes 原生 vs 独立应用)
- Argo Workflows 是一个 Kubernetes 原生的开源容器化工作流引擎。它专为在 Kubernetes 环境中运行而设计,能够直接利用 Kubernetes 的能力来进行资源管理和轻松地扩缩容。
- Apache Airflow 作为一个独立应用程序运行。虽然它可以被容器化并部署在 Kubernetes 上,但它并不原生依赖 Kubernetes 的特性,这意味着在使用 Airflow 时,管理底层资源和扩缩容往往更具挑战性。
2. 工作流设计与编写方式
- Argo Workflows 通过 YAML 文件和 Kubernetes 的自定义资源定义(CRD)来配置,定义每个步骤所在的独立容器。它在处理极其复杂的工作流(如支持循环、递归和条件逻辑)方面表现出色。
- Apache Airflow 的最大优势是“工作流即代码”(Workflows as code)。它主要使用 Python 语言来定义有向无环图(DAG),这使得动态生成管道、测试和版本控制变得非常容易。它提供了极其丰富的操作符(如 Bash、Python、Docker 等)以增强灵活性。
3. 用户界面(UI)
- Apache Airflow 提供了一个非常强大且具交互性的 UI。用户可以在界面上实时监控工作流、查看日志,甚至直接重新运行失败的单个任务,这为调试和优化带来了巨大的便利。
- Argo Workflows 的 UI 相对简单干净。虽然不如 Airflow 功能丰富,但也足以满足日常查看状态、监控进度和查看日志等基础管理需求。
4. 调度机制(Scheduling)
- Argo Workflows 利用 Kubernetes CronJob(或内置的 CronWorkflow)来调度工作流,将资源分配和可靠性保障交由 Kubernetes 底层来处理。
- Apache Airflow 拥有独立的内置调度器。它允许设置更复杂的调度规则和任务依赖,但其调度器的性能和可靠性也高度依赖于安装 Airflow 的机器本身的硬件资源。
5. 社区与支持
- Apache Airflow 由于发布时间较长,作为 Apache 顶级项目,拥有庞大的社区和非常详尽的文档资料,遇到问题时更容易找到现成的解决方案。
- Argo Workflows 社区相对较小,但随着云原生的普及,其用户群正在迅速增长,官方生态和文档也在快速扩展和完善中。
总结
通过这几个简单的例子,我们可以看到 Argo Workflow 的强大之处:
- 云原生:完全基于 Kubernetes CRD,使用 YAML 定义,所有任务都在容器中运行。
- 灵活的数据传递:原生支持 Parameter 和 Artifact,轻松构建复杂的数据流水线。
- 可视化:自带美观且功能丰富的 UI,方便监控和排错。
如果你需要在 Kubernetes 上编排复杂的批处理任务或数据流水线,Argo Workflow 绝对是一个值得深入研究的利器。